Figmaは多大なアクセスをさばくためにどのようにデータベースのスケーリングを行ったのか?
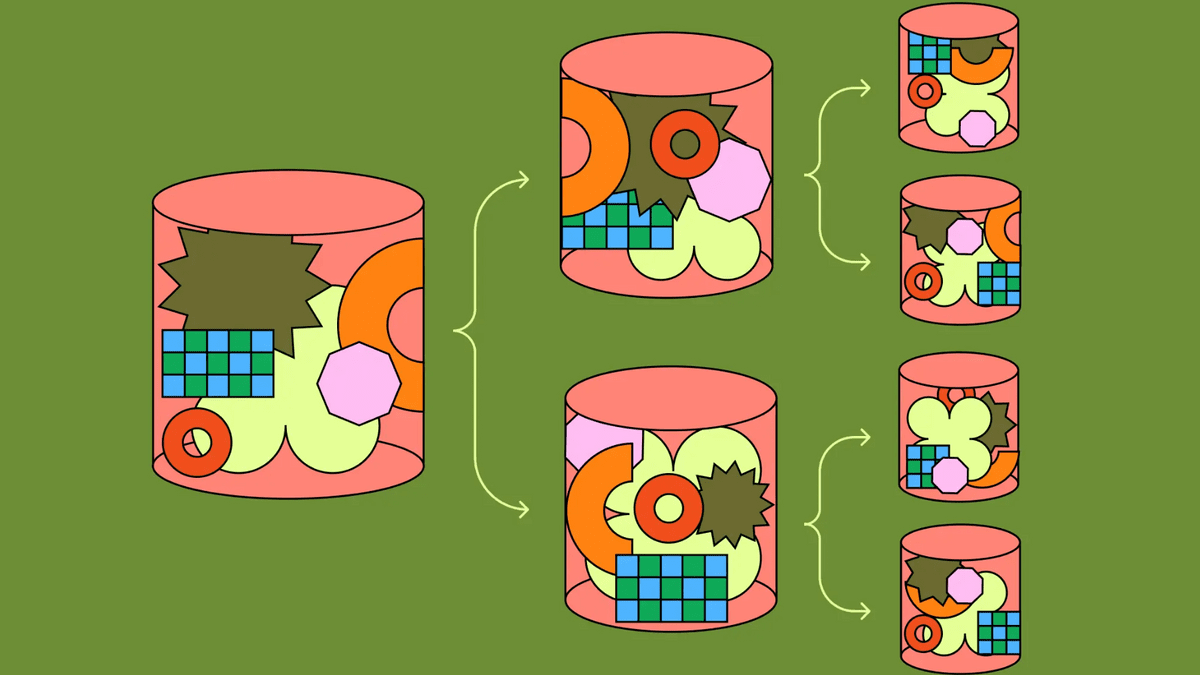
ブラウザベースのデザインツール「Figma」のデータベース(DB)は2020年以来100倍に拡大しました。当初は単一のPostgreSQLで構築されていたDBをどのようにして分散システムへと移行したのかについて、公式ブログで詳しく説明されています。
How Figma's Databases Team Lived to Tell the Scale | Figma Blog
https://www.figma.com/ja-jp/blog/how-figmas-databases-team-lived-to-tell-the-scale/
Figmaではまず、「Figmaファイル」や「組織」などテーブルごとにDBを分割する「垂直分割」を行いました。2022年までに10個のパーティションに分割し、それぞれのパーティションを監視することでスケーリングの優先順位を付けたとのこと。

Figmaの利用者が増加するにつれてテーブル単位での分割では限界が来てしまい、テーブル内のデータを分割する「水平分割」を行う必要がでてきました。アプリケーション側でテーブルを水平に分割することで、物理層で任意の数のシャードを利用できるようになり、スケールを格段に向上させることができます。
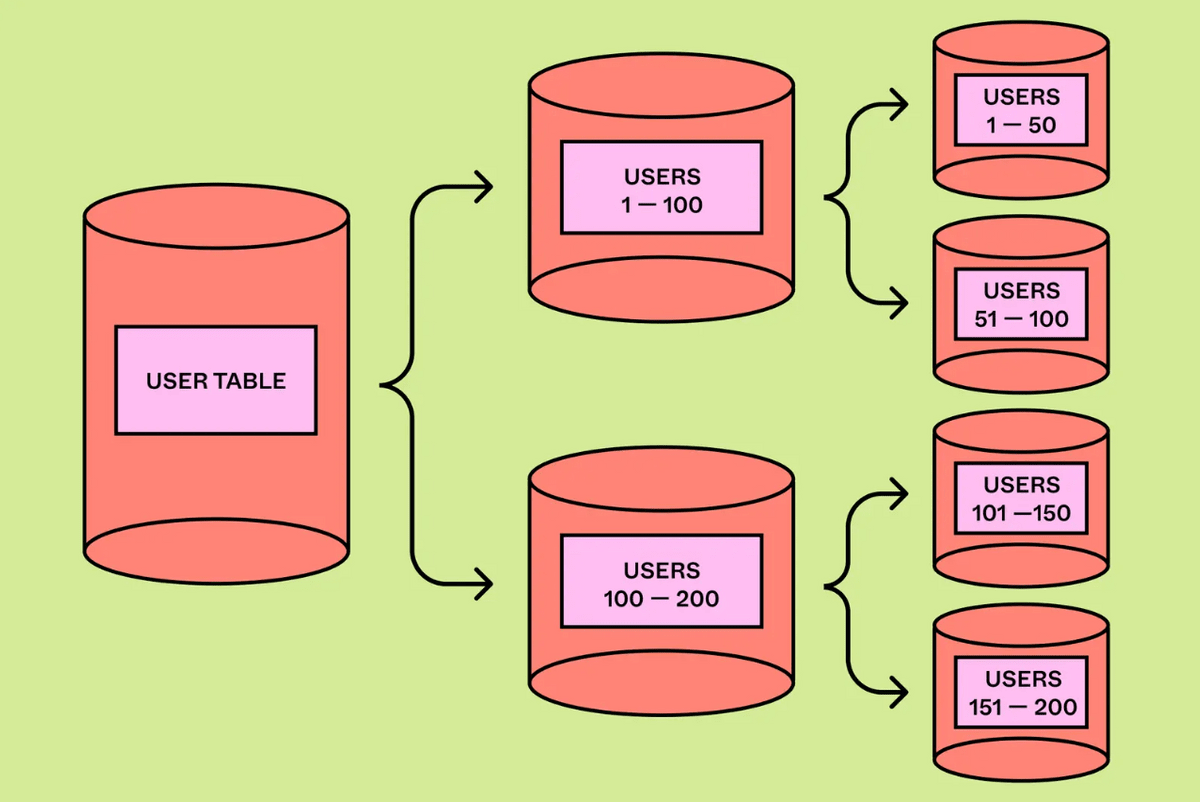
ただし、水平分割を行うことで下記のような問題が発生するとのこと。
・一部のSQLクエリは非効率になるかサポートできなくなる
・正しいシャードにクエリを効率的にルーティングできるような情報を提供するようにコードを更新する必要がある
・外部キーとグローバルに一意なインデックスを強制できなくなる
・複数のシャードにまたがるトランザクションは部分的に失敗する可能性がある
完全な水平分割を実現するのは長い道のりになることが分かっていたため、Figmaの開発チームはまずシンプルながら非常にトラフィックの多いテーブルを水平分割し、DBの負荷を軽減しつつ水平分割の実行可能性を証明しました。チームが最初のテーブルを水平分割するまでに9カ月かかりました。
水平分割を行うと、適切なシャードへクエリをルーティングできるようにほとんどのクエリにシャードキーを含める必要が出てきます。「何をシャードキーとして利用するのか」は適切にトラフィックを分散するために重要な問題です。FigmaではUserIDやFileID、OrgIDなどいくつかのIDをシャードキーとして使用することにしました。
Figmaは「Colos」という概念を導入し、関連するテーブルを同様に水平分割して同じ物理シャードに格納することで、単一のシャードキーを使用するクエリにおいてテーブル間のJoinと完全なトランザクションをサポートできるようにしたとのこと。Colosを使用することでアプリケーションのコード変更も最小限にすることができました。
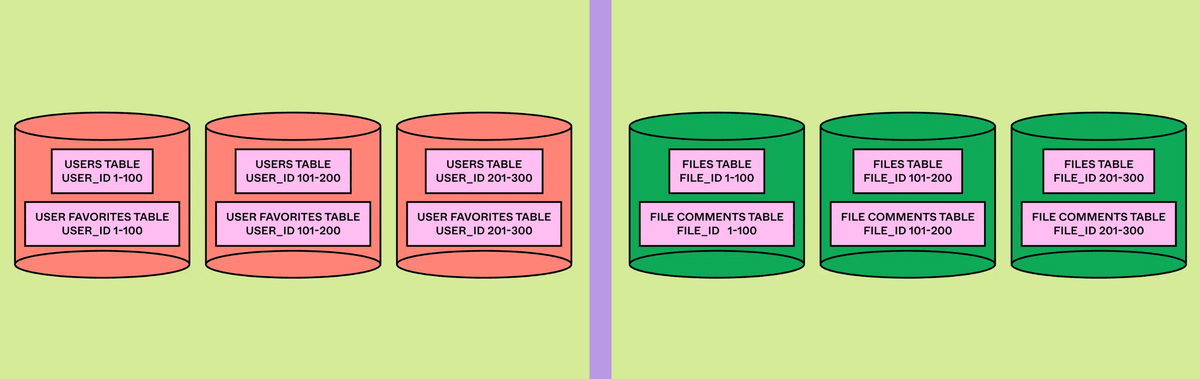
また、シャードキーとして使用する各種のIDは自動インクリメントであったりSnowflakeタイムスタンプをプレフィックスとして含んでいたりしてランダム性が確保されておらず、特定のシャードに負荷が集中する恐れがあったため、ルーティングにはシャードキーのハッシュを使用することにしました。この手法を使用すると連続キーが異なるシャードに配置されるため範囲スキャンの効率が低下しますが、Figmaでは範囲スキャンを必要とするクエリが一般的ではないため許容可能でした。
Figmaでは水平分割を実行する際のリスクを回避するため、アプリケーション層でテーブルを準備するプロセスを実際の分割を行う物理層のプロセスから分離したとのこと。テーブルがアプリケーション層で論理的に水平分割されると、実際には単一の物理シャード上にあってもアプリ側からは既に水平分割が実行されているかのように操作ができます。論理シャーディングを行ってデータが問題なく処理されていることが確認できてから物理的に水平分割を実行しました。

当初、アプリケーションはDBへの接続プーリングレイヤーであるPGBouncerと直接通信していましたが、水平分割を行うと高度なクエリ解析・計画・実行が必要になるため、新たにDBProxyを実装しました。

DBProxyでは負荷軽減や監視、トランザクション、データベーストポロジ管理などの処理に加え、軽量クエリエンジンの機能が含まれていました。クエリエンジンの主なコンポーネントは「クエリパーサー」「論理プランナー」「物理プランナー」とのこと。クエリパーサーはSQLを読み取って抽象構文ツリー(AST)へと変換します。
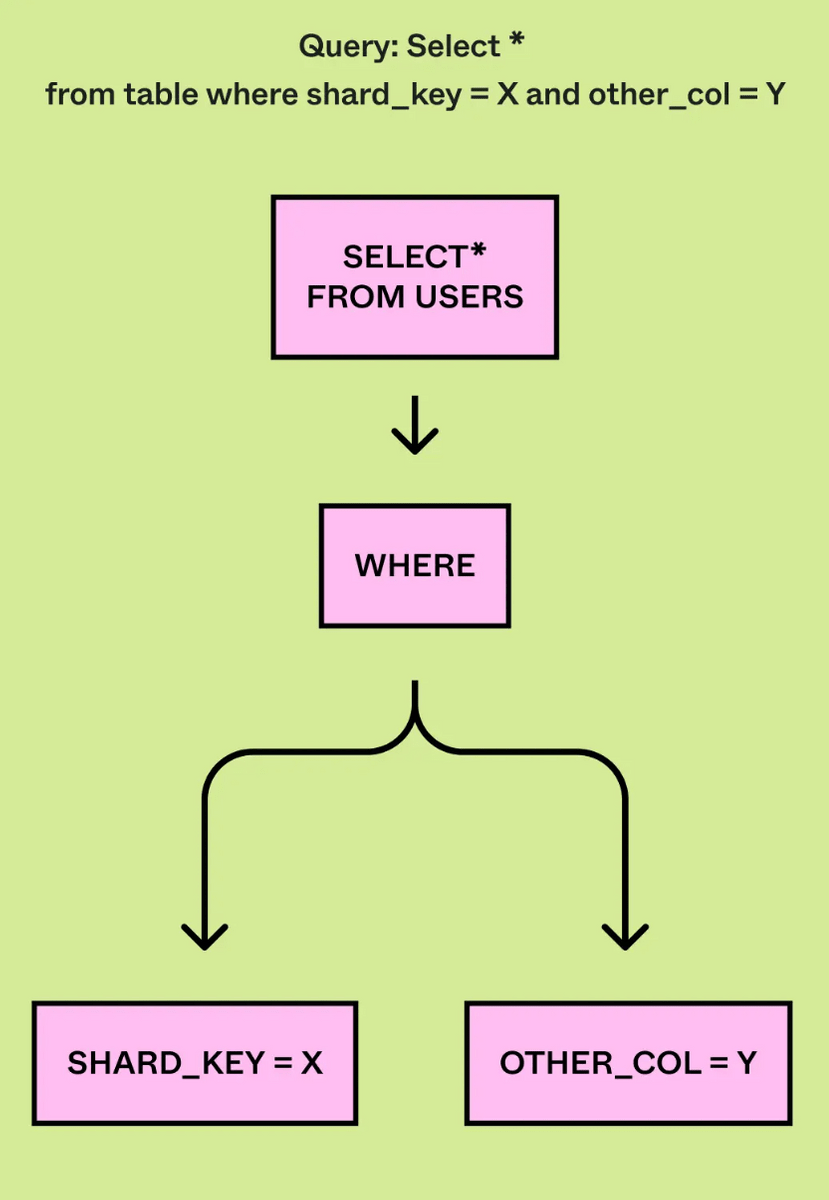
論理プランナーはASTを解析し、クエリプランから「Insert」「Update」などのクエリタイプと論理シャードIDを抽出します。
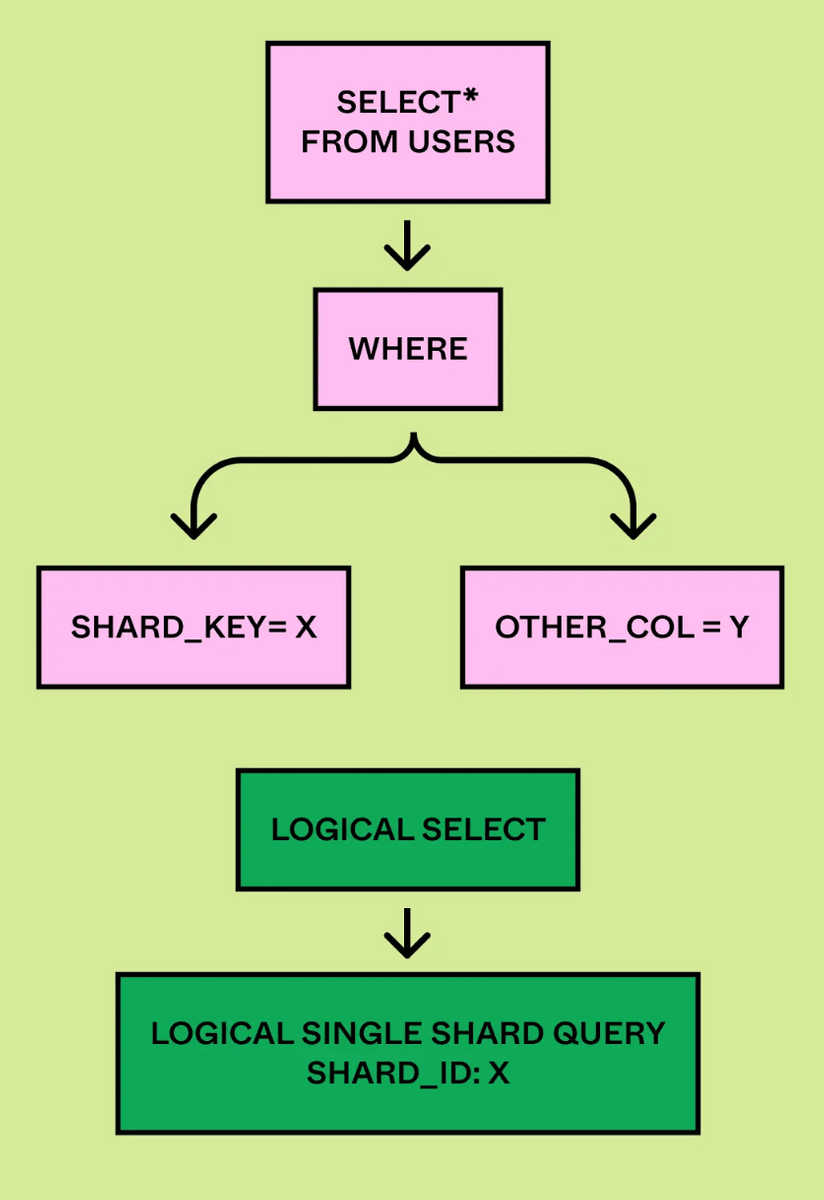
物理プランナーは論理シャードIDから物理データベースにクエリをマップし、適切な物理シャードで実行するようクエリを書き換えます。
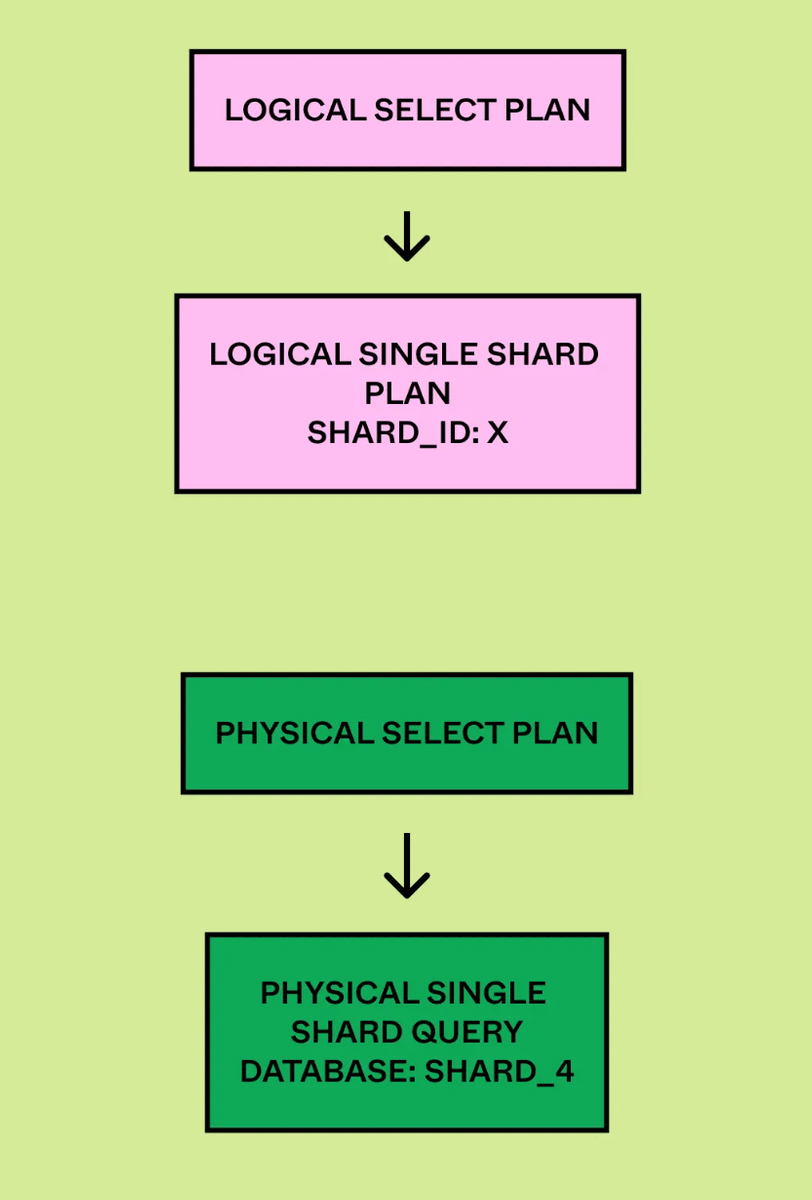
クエリが単一シャードクエリであればクエリエンジンの仕事はシャードキーを抽出し、クエリを適切な物理シャードにルーティングするだけですみます。
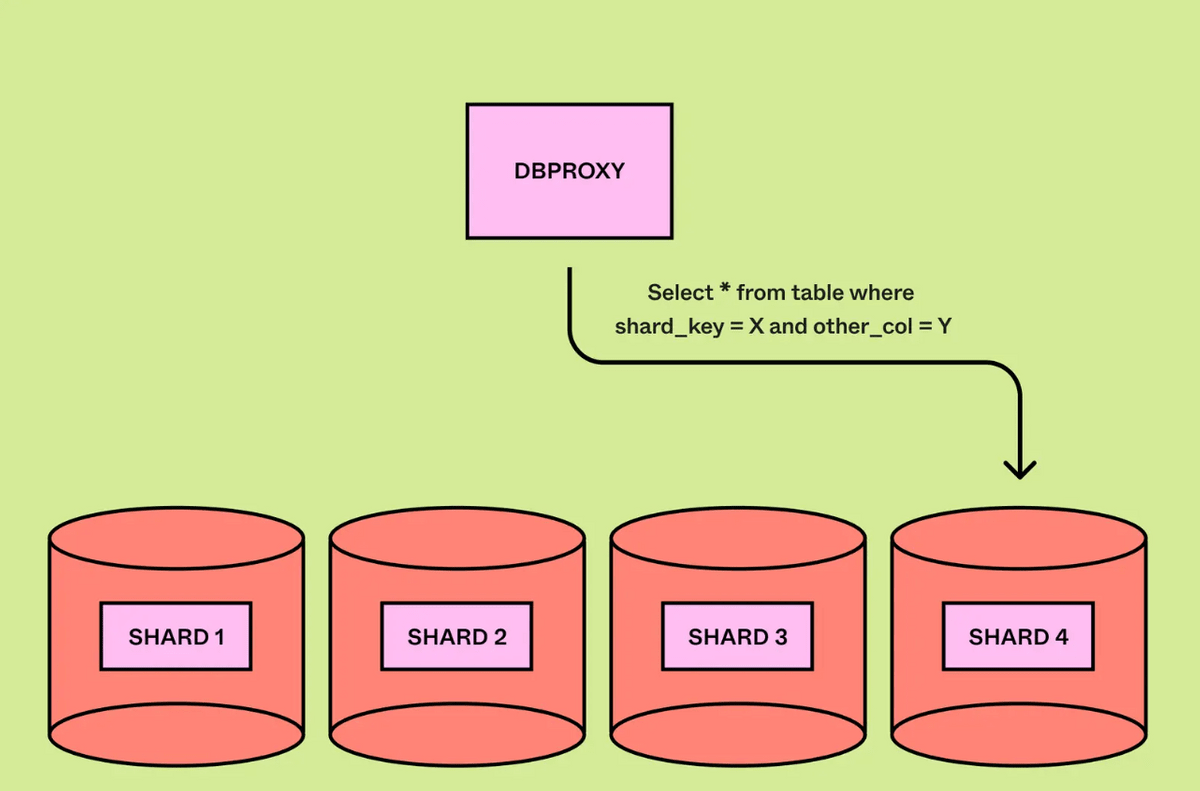
一方、複数のシャードにまたがって処理する必要があるクエリの場合、クエリエンジンは全てのシャードにクエリを渡し、結果を集計する必要があります。複数のシャードにまたがるクエリはデータベースが分割されていない時と同じ負荷が発生してしまいます。
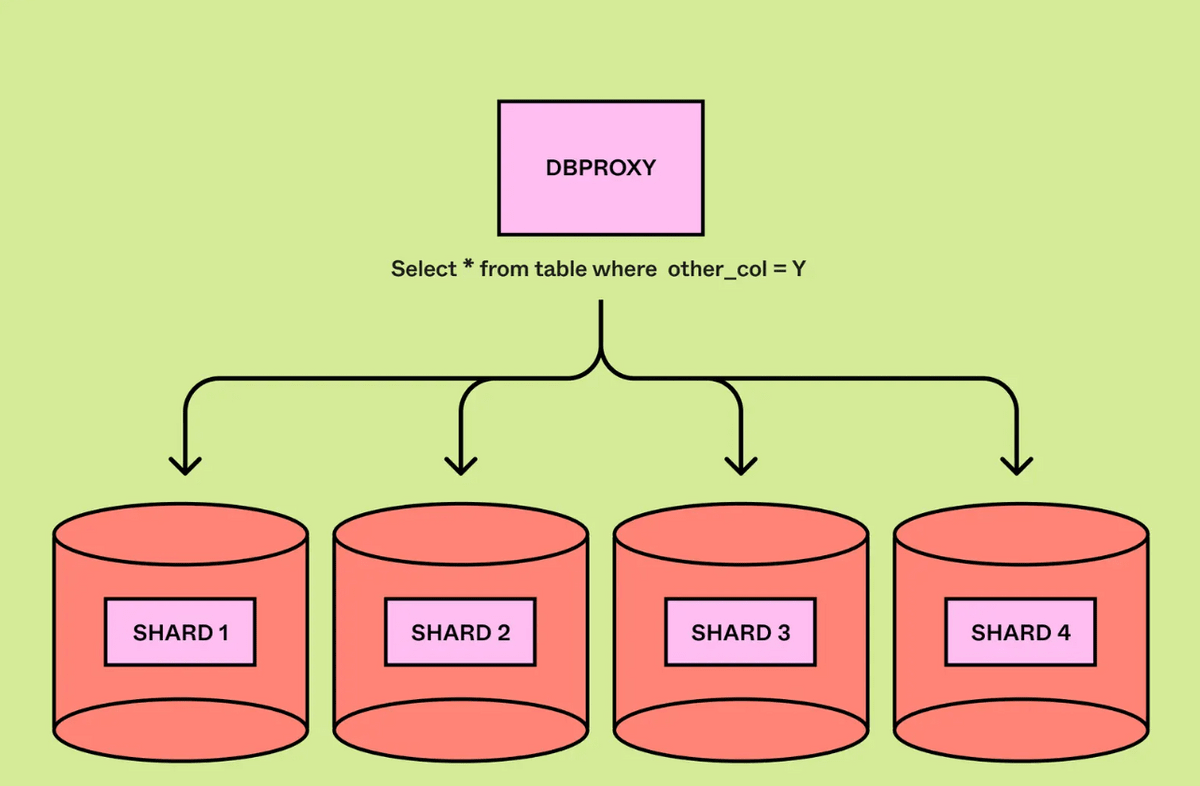
論理シャードのカプセル化にはPostgreSQLの「view」機能を使用したとのこと。シャード分割に対応するようにDBの一定範囲のみを参照する複数のviewを作成し、書き込み・読み取りをview経由にすることであたかもシャードが既に分割されているかのように操作できます。クエリエンジンの機能フラグを使用して段階的にロールアウトすることで、リスクを抑えて適切な水平分割が実行されているかを確認できたとのこと。
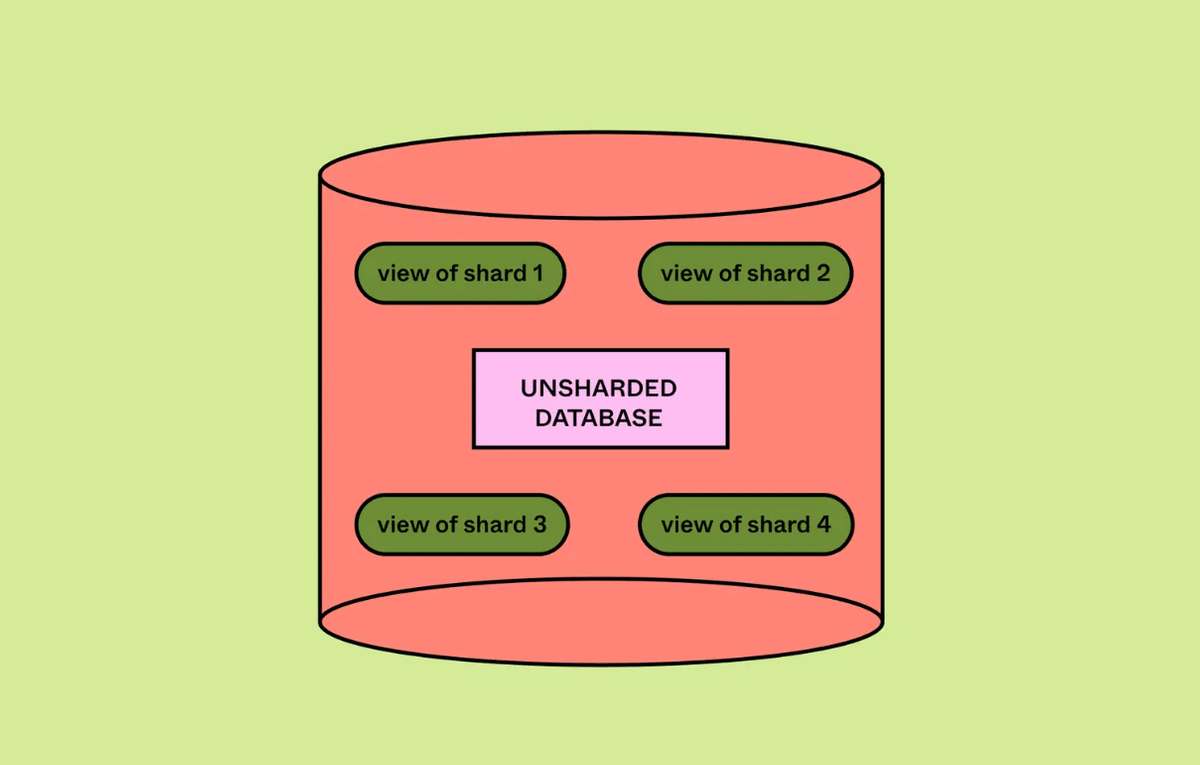
適切なクエリルーティングを実行するために、DBProxyはテーブルと物理データベースの関係を把握しておく必要があります。垂直分割を行った際にはどのテーブルがどのパーティションに配置されているかを構成ファイルにハードコーディングしていましたが、水平分割ではシャードの分割中に接続関係が動的に変化するため、間違ったシャードにルーティングされないよう迅速に関係を更新する必要がありました。Figmaでは水平分割のメタデータをカプセル化し、1秒以内にリアルタイム更新できるようにしています。
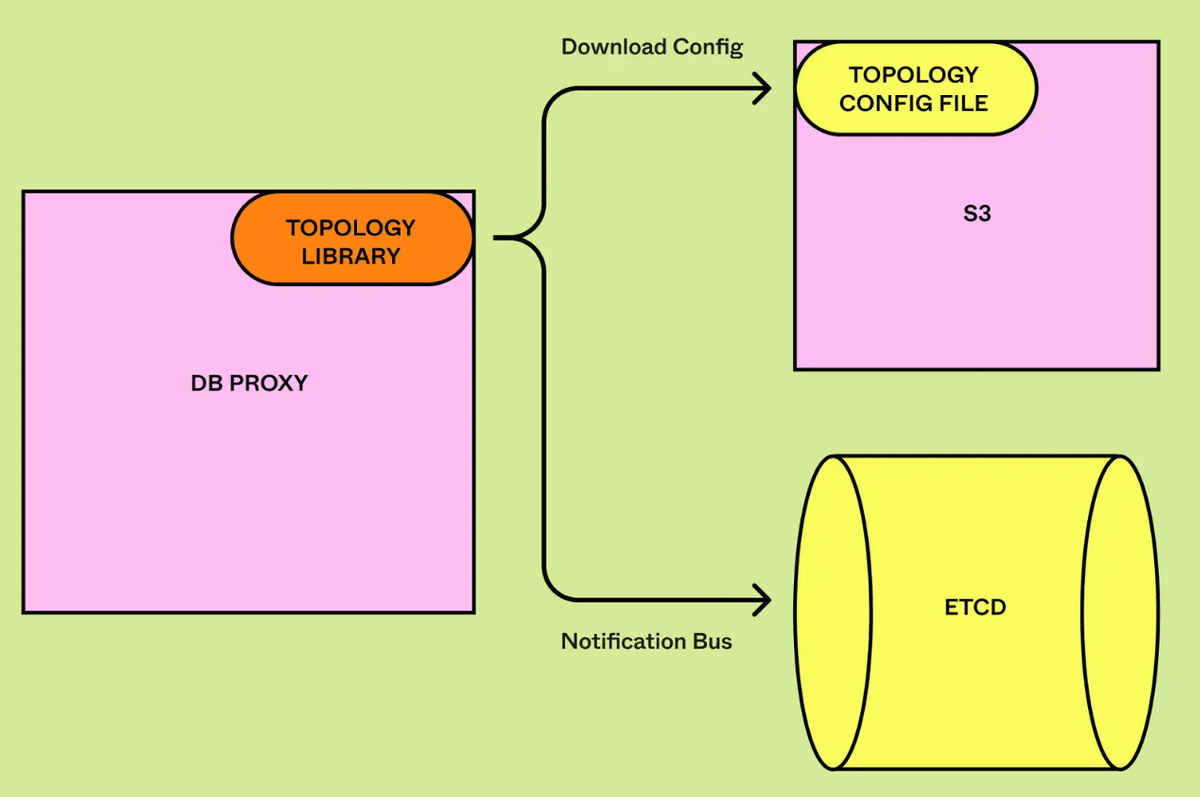
水平分割の準備ができたら、最後に元のDBからシャードされた物理DBへのフェイルオーバーを行います。Figmaでは2023年9月に最初の水平分割を行いました。可用性への影響はプライマリでわずか10秒であり、レプリカ側の可用性には影響がなかったとのこと。また、水平分割後のレイテンシーや可用性の低下はありませんでした。
Figmaは2024年に数十のテーブルと数千の呼び出しサイトを持つ複雑なDBの水平分割に取り組むとし、「最後のスケーリング制限を取り除き、真に飛躍するにはFigmaの全てのテーブルを水平方向に分割する必要がある」と述べました。
・関連記事
データベース用語の「シャーディング」はMMORPGの「ウルティマオンライン」が由来かもしれない - GIGAZINE
UUIDなのにデータベースのプライマリキーに設定してもパフォーマンスの問題を起こさない「UUIDv7」の標準化作業が進行中 - GIGAZINE
データベースの文字数制限が191文字になっている理由とは? - GIGAZINE
「16文字以内で最強のパスワード」は本当に最強のパスワードなのか? - GIGAZINE
オープンソースのリレーショナルデータベース「PostgreSQL」が信頼を獲得して広く利用されるようになるまでの歴史をエキスパートエンジニアが解説 - GIGAZINE
・関連コンテンツ